New Situation, Same Elite College Admissions Offices
How AI detection reinforces a century of class bias in elite college admissions — and why the chatbot is just the latest test of who passes.
When Cornell and Carnegie Mellon researchers ran 81,663 college applications through a custom AI detector, they found something the elite admissions industry would prefer no one notice: if a lower-income student submits a top-notch essay, they are presumed to have used AI, but if a rich one does, they are merely suspected. Per unit of estimated LLM use, lower-SES applicants saw their admission odds collapse by 83 percent, whereas their wealthier peers absorbed a milder 62 percent hit.
The paper makes a compelling argument for widespread use of LLMs in college applications, because there's no other way to explain these rapid shifts:
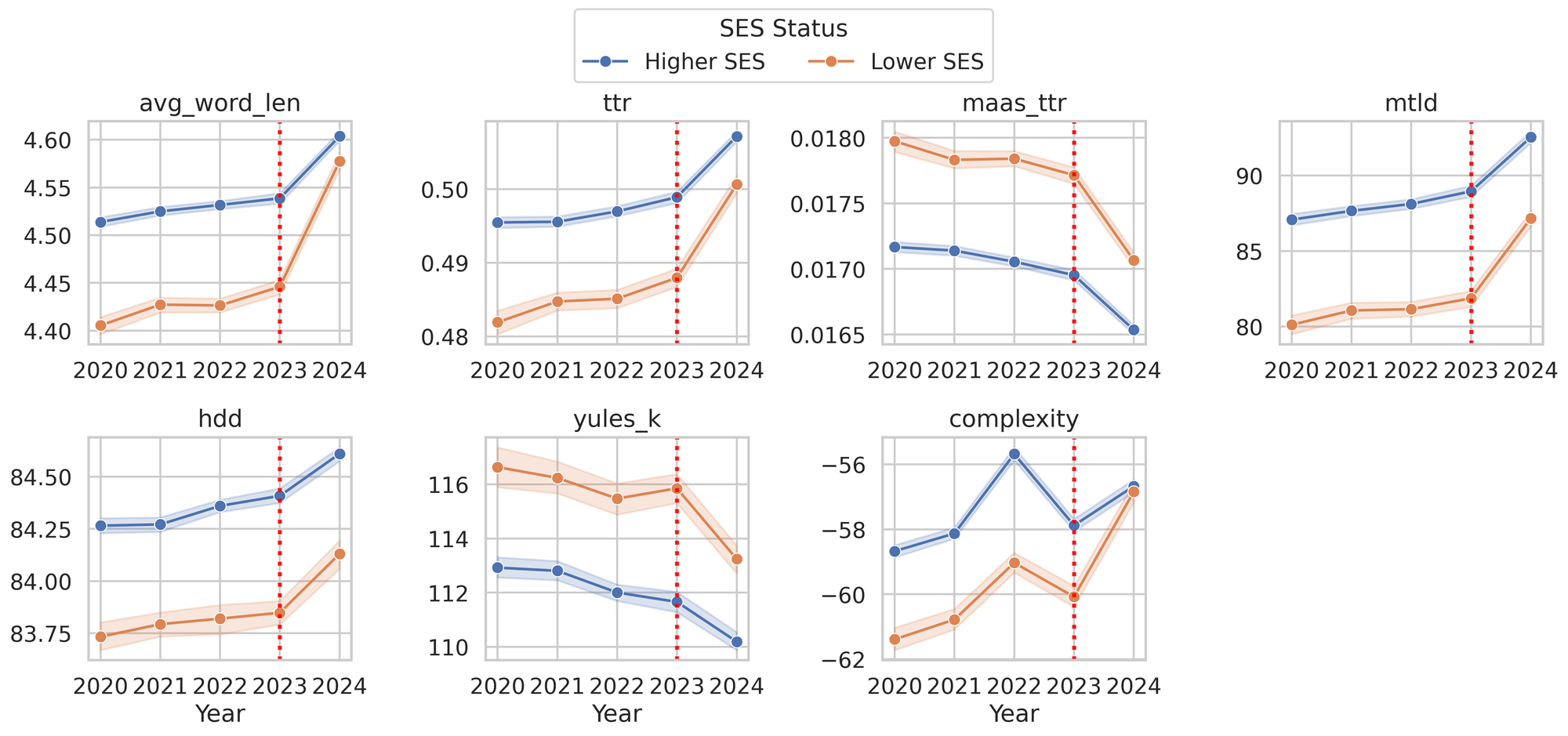
These are all measures of lexical diversity, like average word length, type–token ratio (TTR), Maas TTR, MTLD, HDD, Yule's K, and a complexity measure of 1 - FleschReadingEase. Two points to note:
- The whole pool shifted dramatically in 2024, indicating widespread use of LLMs by both lower- and higher-SES applicants.
- Some of these measures are too subtle for a typical reader to notice—few people will notice if a 500-word essay has a Maas TTR of 0.0175 or 0.165—but average word length and Flesch Reading Ease are both immediately apparent to every reader. Thus, in the eyes of admissions officers, lower- and higher-SES applicants in the 2024 pool were writing at the same level.
Thus, the rise of tools like ChatGPT should have leveled the playing field, helping lower-SES students match the lexical sophistication of peers with access to expensive coaching and editing resources.
But that's not what happened. Once lower-SES students started submitting essays with the same level of lexical diversity as higher-SES students, the class gap at the school widened from 10.7 points to 14.0 points. Higher-SES applicants' admit rates rose 2.7 percentage points after GPT; lower-SES applicants' rates fell 0.6 points. And when Jinsook Lee and her co-authors stripped out the obvious linguistic differences—sentence length, vocabulary, lexical diversity—those observable features explained only 7.1 percent of the disparity. The prose is not the reason for the punishment.
This finding lands inside a story that selective American admissions offices have spent a century working to obscure. The official rationale for the LLM penalty—protecting "authentic voice," guarding against fraud, et cetera—collapses on contact with the data. Lee et al. document that essays are converging linguistically across class lines (the convergence is sharpest among rejected and fee-waiver applicants), that the wealthy use AI too, and that the surface text isn't where the penalty lives. So where does it? The honest answer requires admitting what Jerome Karabel, Daniel Golden, Peter Arcidiacono, Raj Chetty, and a small army of investigators have already shown: holistic admissions at selective American universities is not a meritocracy with rough edges. It is a sorting mechanism whose architecture—invented in the 1920s to keep Jewish students out of Harvard, refined for a century to protect legacies, athletes, and donors' children—was always going to do exactly what it is now doing to poor kids using AI to proofread their essays. The technology is new; the machine is not.
I. We don't know how admissions offices use AI detectors, but we know AI detectors are bad
The most charitable reading of the LLM-penalty finding is that admissions offices are catching cheaters and lower-SES applicants happen to cheat more clumsily. That reading does not survive the empirical record on AI detection.
In July 2023, Stanford's Weixin Liang and colleagues published in Patterns a now-canonical study of seven widely deployed GPT detectors (including GPTZero, OpenAI's classifier, and several commercial tools). On 91 TOEFL essays written by Chinese students, the detectors hit a 61.22 percent average false-positive rate. Every one of the seven detectors unanimously flagged 19.78 percent of the TOEFL essays as machine-written; at least one detector flagged 97.80 percent. On native-speaker eighth-grade essays, the detectors were near-perfect. When Liang's team simply asked ChatGPT to "elevate the provided text by employing literary language" on the same TOEFL essays, the false-positive rate cratered to 11.77 percent. The detectors weren't measuring AI authorship; they were measuring linguistic privilege.
OpenAI quietly conceded the technology didn't work. Its own AI Classifier launched January 31, 2023, and was killed July 20, 2023, "due to its low rate of accuracy." OpenAI's own evaluation on its internal "challenge set": the tool correctly identified 26 percent of AI-written text and falsely accused human writers 9 percent of the time. Turnitin, which sells AI detection at scale to universities, claims a sub-1 percent false-positive rate. The Markup's Tara García Mathewson tested that claim with Johns Hopkins lecturer Taylor Hahn, who watched Turnitin label more than 90 percent of one student's paper as AI despite drafts and notes proving authorship. Hahn told The Markup that "Turnitin's tool was much more likely to flag international students' writing as AI-generated." Annie Chechitelli, Turnitin's chief product officer, made the underlying mechanism plain: the model "ends up learning that more complex writing is more likely to be human." The corollary is unspoken but undeniable: simpler writing—the writing of non-native speakers, of working-class kids, of teenagers without $300-an-hour essay coaches—is more likely to be flagged as machine.
Independent peer-reviewed testing by Weber-Wulff and colleagues, published in the International Journal for Educational Integrity in late 2023, found none of fourteen popular detectors broke 80 percent accuracy; only five passed 70 percent. Vanderbilt has publicly disabled Turnitin's AI tool, declaring it "not an effective tool that should be used." At least a dozen other institutions—including Northwestern, Johns Hopkins, Notre Dame, and UCLA—have disabled or actively discouraged faculty use. Wrongful accusations have piled up at UC Davis, Texas A&M-Commerce, Cardozo Law, NYU, and Miami University. Stony Brook's Shyam Sharma told The Markup the obvious: "The victim here is less worthy of a second thought."
Whether admissions offices actually use these tools, and how, is harder to map because admissions offices provide little to no information about their actual processes. But we do know AI use is widespread in admissions: a September 2023 Intelligent.com survey of 399 education professionals found that 82 percent of their institutions either already used AI in admissions or planned to by 2024. Coverage by Inside Higher Ed and U.S. News reported that 60 percent of respondents whose schools use AI said they used it to review personal essays. UNC-Chapel Hill has been AI-scoring essays since 2019; Virginia Tech began a hybrid AI-human scoring model in the 2025–26 cycle; Caltech is using AI to evaluate applications, per Bloomberg's January 2026 reporting. Slate, the dominant admissions CRM, ships an embedded "Reader AI." Pangram Labs, a newer entrant boosted by a University of Chicago Becker Friedman working paper, is replacing Turnitin in some admissions offices.
The detection bias documented by Liang et al. is not abstract; it is likely being operationalized inside the rooms where decisions get made. For all we know, entire applicant pools are being dumped into AI detectors and the rampant false positives used to cut workload. Nothing stops schools from publicly stating they won't use these products, or at least explaining how they do.
II. "Authenticity" as a class test
But detection bias alone cannot explain the size of the penalty Lee et al. measured. The mediation analysis is telling: stylometric features account for only 7.1 percent of the differential. Most of the punishment lives in human readers—and in the priors those readers bring.
The most rigorous experimental work on admissions reader behavior comes from Michigan's Michael Bastedo and colleagues. Their 2018 Journal of Higher Education study surveyed 311 admissions officers from 177 institutions in the top three Barron's selectivity tiers and found three competing definitions of "holistic review"—whole file, whole person, whole context—splitting 50 / 19 / 29 percent respectively. Only the 29 percent "whole context" approach actually considers neighborhood, school resources, and family hardship. The other 71 percent default to cognitive heuristics in conditions of ambiguity, and as Bastedo told the Chronicle of Higher Education: "Admissions work is all full of ambiguities." Cognitive psychology is unambiguous about what fills that ambiguity: stereotypes, including those about who "should" sound polished and about whose adversity is convincing. If a school doesn't bother to establish a real methodology for "holistic review," it's not even trying to remain objective.
The empirical anchor for the class-coding of essays is AJ Alvero, Sonia Giebel, Mitchell Stevens, and Ben Domingue's 2021 Science Advances paper, which read 240,000 essays from 60,000 University of California applicants. Essay content and style correlated more strongly with self-reported household income than SAT scores did. Wealthy students wrote about "thematically abstract" subjects like "seeking answers" and "human nature." Lower-income students wrote about interpersonal relationships, school issues, time management. As Giebel told The New York Times, "class patterns are likely to be present across all the elements used to make admissions decisions." The essay was a wealth test before AI existed.
Alvero's follow-up work in Journal of Big Data (September 2024) compared 150,000 human essays to LLM outputs and found that AI-generated essays "sound" most like male, private-school, higher-SES applicants—longer words, less variation, the polished register of inherited cultural capital. This is the perceptual trap baked into the entire enterprise: detection algorithms (calibrated on perplexity) and human readers (calibrated on what "an essay" sounds like) are both anchored in the linguistic profile of the wealthy white private-school applicant. When a working-class kid produces that register—through a teacher's edits, hard work, or yes, a free ChatGPT session—it doesn't fit. The student is presumed inauthentic.
Columbia/Ohio State sociologist Tiffany Huang's 2024 paper in Sociology of Education names this directly: the "authenticity paradox." Huang interviewed independent educational consultants and found a relentless coaching pattern in which lower-SES and minority students must perform identity to satisfy reader expectations but not in ways that read as performance. Her conclusion: "Class and racial inequality can be embedded in students' varying abilities to leverage subjective application components as a means of sending the 'correct' signals to colleges." The narrow corridor she describes—adversity narrated, but in a reflective, ironic, literary register—is the same one Jeffrey Selingo's Who Gets In and Why describes admissions readers using to recognize "people who remind them of themselves." This is similarity bias with a literary vocabulary.
In April 2025, Cornell's Kowe Kadoma, Penn's Danaé Metaxa, and Cornell Tech's Mor Naaman published the most direct test of the perception side. Their CHI '25 paper, Generative AI and Perceptual Harms: Who's Suspected of Using LLMs?, ran three experiments asking participants to evaluate fictional freelance writers. Writers suspected of AI use received lower quality evaluations and decreased hiring likelihood across every demographic group studied—independent of whether they had actually used AI. In the nationality experiment, East-Asian-coded profiles were suspected at a higher rate than U.S./white-American profiles (42.0 percent vs. 35.1 percent; p < 0.001). As Naaman distilled it: "If you are suspected of using AI, your outcomes will be worse." Admissions offices are wholly opaque, so suspicion alone is guilt and punishment. The technology hasn't created a new bias; it has given an old one a new alibi.
III. The past isn't even past
To understand why the alibi is being deployed exactly the way it is, the indispensable text is Berkeley sociologist Jerome Karabel's The Chosen (Houghton Mifflin, 2005). Karabel documented that "holistic admissions"—the very system whose discretion now produces a 1.85-fold LLM penalty for the poor—was invented at Harvard, Yale, and Princeton in the 1920s as a tool for keeping Jewish students out. By the early 1920s, Jewish enrollment had reached roughly 21 percent at Harvard, around 40 percent at Columbia. Harvard President A. Lawrence Lowell tried explicit quotas; the faculty pushed back. So Lowell pivoted to evaluating "character," introducing the personal essay, the alumni interview, the recommendation letter, the photograph, the geographic-diversity quota. An anonymous Harvard alumnus wrote that "to find that one's University had become so Hebrewized was a fearful shock." Lowell himself defended the policy with what would become his signature analogy: "The summer hotel that is ruined by admitting Jews meets its fate, not because the Jews it admits are of bad character, but because they drive away the Gentiles."
The other Ivies followed. Yale, under admissions chairman Robert Corwin, maintained an informal cap of roughly 10 percent on Jewish enrollment beginning in the early 1920s; Corwin in 1929 grumbled that admit lists "read like some of the 'begat' portions of the Old Testament," and the next year limited Jewish enrollment to 8.2 percent, hailed as having been attained "without hue and cry." Columbia cut its Jewish enrollment from roughly 40 percent before 1920 to around 20–22 percent by the early 1920s, with further declines later in the decade. Princeton, without ever putting it in writing, suppressed Jewish enrollment to roughly 3 percent throughout the decade. Dartmouth, under President Ernest Martin Hopkins, imposed an internal Jewish quota of roughly 5–6 percent per entering class by 1932–33, enforced through racial and religious questions on applications and required photographs.
The point is structural: the discretionary, unscientific, "we-know-it-when-we-see-it" framework of holistic admissions was designed to give selective universities room to discriminate while denying the discrimination. It was always going to be weaponizable against whichever group threatened the social position the institutions exist to reproduce. In 1925 the threat was Jewish kids. In 1980 it was, increasingly, Asian-American kids—Arcidiacono's SFFA expert reports established that Harvard's "personal rating" systematically scored Asian-American applicants lower despite stronger academic credentials. In 2026 the threat is poor kids who figured out ChatGPT.
Stanford sociologist Mitchell Stevens, who spent 18 months embedded in admissions at a "bucolic New England" liberal-arts college (Hamilton), put it bluntly in Creating a Class: elite admissions runs on "systematic preferencing" in service of "organizational machinery in place to pass comfortable social positions on to their children." Affirmative action, he wrote, was "the least of it."
IV. Wealth's thumb on the scale
The argument that the LLM penalty reflects ordinary meritocratic vigilance has to be measured against what selective American universities actually do with their admissions slots. The empirical answer—extracted from Harvard's own data during Students for Fair Admissions v. Harvard—is devastating. Drawing on six cycles of internal Harvard data, Peter Arcidiacono and his co-authors documented these admit rates:
- Overall: ~6 percent
- Legacies: 33.6 percent—which the authors state is "5.7 times higher than the admit rate for non-legacy applicants"
- Recruited athletes: 86 percent—roughly 14.6 times the ~5.9 percent non-ALDC baseline
- Dean's Interest List (donor-related): 42.7 percent
- Children of faculty/staff: 46.7 percent
The "ALDC" categories—Athletes, Legacies, Dean's interest, Children of faculty—comprised roughly 5 percent of applicants but about 30 percent of admits. Approximately 43 percent of white admits were ALDC. Arcidiacono concluded that roughly three-quarters of white ALDC admits would have been rejected without their preference status. Justice Neil Gorsuch's SFFA concurrence put the same fact in the official record: legacy/donor/faculty preferences "undoubtedly benefit white and wealthy applicants the most" yet account for "around 30 percent of the applicants admitted each year." A 2013 internal Harvard study made public in litigation showed legacy status boosted admission odds slightly more than being Black and nearly twice as much as being Hispanic. Harvard's own 2013 Office of Institutional Research analysis—put to Dean William Fitzsimmons during cross-examination at the SFFA trial—showed that, among applicants in the top two academic ratings, the admit rate climbed from a 15 percent non-legacy/non-disadvantaged baseline to 24 percent for low-income applicants and 55 percent for legacies.
Then there is the Z-list—Harvard's deferred-admission backdoor of 50–60 students per year, 70 percent white, 2 percent Black, 46.5 percent legacy, with academic records "more comparable to rejected students" (per The Harvard Crimson's reading of the trial documents) than admitted ones. Bev Taylor, founder of Ivy Coach, told the Boston Globe in July 2018 that her Z-listed clients had families willing to donate "anywhere from $1 million over four years to several millions."
Daniel Golden's Pulitzer-winning Wall Street Journal series in 2003–04, his 2006 book The Price of Admission, and his November 2016 ProPublica exposé documented the donor side with names. Charles Kushner pledged $2.5 million to Harvard in 1998, paid in $250,000 annual installments, around the time son Jared was applying. A Frisch School official told Golden: "There was no way anybody in the administrative office of the school thought he would on the merits get into Harvard." Margaret Bass, daughter of Stanford trustee chair Robert M. Bass—who had given Stanford $25 million in 1992—was the only one of nine Groton applicants admitted to Stanford in 1998 (40th in her Groton class, 1220 SAT). SFFA filings exposed an internal Harvard email from a former dean to Fitzsimmons, subject line "My Hero": "Once again you have done wonders. I am simply thrilled about the folks you were able to admit. [Redacted] has already committed to a building."
In Operation Varsity Blues, federal prosecutors charged 33 wealthy parents in March 2019 with paying $25 million in bribes to William "Rick" Singer. Lori Loughlin and Mossimo Giannulli paid $500,000 to designate two non-rowing daughters as USC crew recruits. Bill McGlashan, co-founder of the Bono/Skoll-affiliated TPG Rise Fund, paid to fake-recruit his son to USC football. The scandal was structurally minor—a kludgy side-door—but morally clarifying. Singer cooperated. The deeper machine—legacy, donor, athletic preferences—operated lawfully throughout.
Then there is the Chetty/Friedman/Deming megastudy. Raj Chetty, John Friedman, and David Deming linked IRS records, College Board scores, and confidential admissions data across the eight Ivies, Stanford, MIT, Duke, and Chicago. Their July 2023 NBER paper found children of top-1 percent families ($611,000+) more than 2.2 times as likely to attend an Ivy-Plus college as middle-class peers with the same SAT scores. The drivers: legacy preferences (~46 percent of the gap), non-academic ratings driven by private-school extracurricular profiles (~31 percent), athletic recruitment (~24 percent). Recruited athletes constitute 5 percent of admits from the bottom 60 percent of the income distribution but over 13 percent of admits from the top 1 percent.
The athletic premium concentrates in what The Harvard Crimson candidly calls "aristocrat sports." A Wall Street Journal analysis found roughly 90 percent of Ivy League squash players attended private high schools with $30,000-plus tuition; two-thirds of Ivy lacrosse and crew athletes did the same. Sailing, fencing, equestrian, golf, water polo, skiing, tennis—the recruiting roster is essentially a country-club roster.
Early Decision—binding admission that prevents financial-aid comparison—reinforces the same pattern. Penn admits over half its class through ED; Duke admitted roughly half the Class of 2030 through ED; Northwestern admitted more than half the Class of 2029 through ED; Tulane has shifted from filling roughly a quarter of its class through ED in 2017 to more than two-thirds by 2022. James Murphy of Class Action has documented that students at private high schools are 3.5 times more likely to apply ED than public-school students. Virginia Tech eliminated both legacy and ED in August 2023. Most peer schools have not.
V. SFFA's essay carveout and the new race-via-class proxy war
The Supreme Court's June 2023 SFFA v. Harvard ruling did not abolish race-conscious admissions in practice; it pushed it underground, into the essay. Chief Justice Roberts wrote that "nothing in this opinion should be construed as prohibiting universities from considering an applicant's discussion of how race affected his or her life," a passage Justice Sotomayor's dissent dismissed as "lipstick on a pig." Within weeks, Harvard scrapped its open-topic optional supplement and introduced five new short answers, the first asking how "the life experiences that shape who you are today" would contribute. Yale rolled out three rotating prompts on community and lived experience. Brown asked about "where they came from." Dartmouth opened a prompt with "It's not easy being green." Stanford, Columbia, Penn, Duke, Hopkins, MIT all retained or amplified prompts on contribution to diversity.
University of Chicago Law professor Sonja Starr's 2025 Indiana Law Journal study reviewed prompts at 65 top colleges over four years and surveyed 881 applicants. Diversity, identity, and adversity prompts are "prevalent and increasing." But the elimination of explicit race-conscious admissions has produced exactly the demographic results SFFA wanted. MIT's Black enrollment dropped from roughly 15 percent to 5 percent in the Class of 2028. Amherst's Black enrollment fell from 11 percent to 3 percent. Tufts: 7.3 percent to 4.7 percent. Pomona: 9.8 percent to 5 percent. Brown: 15 to 9 percent. MIT Dean Stu Schmill wrote, in a public moment of candor: "I have no doubt that we left out many well-qualified, well-matched applicants from historically under-represented backgrounds." Princeton's Black enrollment fell to roughly 5 percent—the lowest since 1968. James Murphy's Class Action analysis of Ivy-Plus institutions found underrepresented-minority freshman enrollment fell 18.9 percent between 2023 and 2024; at Carnegie Mellon, Black first-year enrollment fell nearly 50 percent.
This is the soil in which the LLM penalty is now growing. The new essay-centered review process demands that lower-SES applicants—disproportionately Black, Hispanic, immigrant, ESL—perform identity and adversity in writing. As Code Switch described it, "in college admission, trauma is shorthand for Blackness." Black students are expected to show how they fit precisely into the stereotypical molds admissions offices anticipate—but then admissions offices also penalize them when their performance reads as too good, and thus presumably coached or AI-assisted. It is a closed loop. As one BestColleges analysis warned, post-SFFA prompts forcing 200- to 250-word adversity narratives "might cause students to rely on stereotypes and hackneyed anecdotes meant to satisfy admissions officers' expectations… The results might read like something spit out by ChatGPT." That is exactly the trap.
Anthony Carnevale of Georgetown's CEW, Richard Kahlenberg (the SFFA expert witness who has spent two decades arguing for class-based affirmative action), and Tufts sociologist Natasha Warikoo have all warned that SFFA's essay carveout effectively redistributes admissions advantage within minority pools toward better-resourced applicants—the "Privileged Poor" Anthony Jack of Harvard catalogued in his 2019 book of that name. Jack has documented that roughly half of poor Black students and a third of poor Latinx students at selective colleges actually attended elite boarding, day, and preparatory high schools, while the rest are "doubly disadvantaged" by under-resourced public schools. The distinction cuts directly through the LLM-penalty data. The privileged poor know how to use a chatbot the way one uses a research assistant. The doubly disadvantaged type "hello" and "thank you"—exactly what Bassignana et al. measured.
VI. The AI consultant economy and the prompting gap
When the wealthy started using ChatGPT for college essays, the consulting industry it underwrote did not collapse—it pivoted. The Independent Educational Consultants Association estimates roughly 25,000 consultants working in the U.S.; IBISWorld puts the industry at $2.9 billion, up from $400 million a decade ago. Crimson Education, founded by Harvard alum Jamie Beaton with Larry Summers as advisor, sells $30,000-and-up undergraduate packages and has been valued near $600 million. IvyWise starts at roughly $1,500 for an initial consultation, with full packages running well into five figures. Command Education's founder Christopher Rim charges parents of his roughly 190 mostly Manhattan and Brooklyn private-school clients $120,000 per year for "white-glove" service—"We are texting students, I think it's like 15 minutes before their math class, to make sure they turn in their homework," he told New York Magazine—before responding to the obvious objection: "Yes…but an unfair advantage over other rich students." Top-end packages started in middle school can run $500,000 to $750,000, per CBS News reporting.
These firms have absorbed AI fully. Crimson's Deltaschool AI division is openly run by director George Gatsios, who describes "the three of us—ChatGPT, my student, and myself—to generate hundreds of ideas." The meta-skill being sold is how to use AI for ideation and refinement, not production; how to make AI-edited prose retain the student's "voice"; how to route output through humanizers to evade detection. Whole submarkets exist for the last step—Undetectable.ai, StealthGPT, HIX Bypass, Phrasly, Walter Writes, Ryne, WriteHuman—running $9 to $25 a month.
The prompting-skill gap is not anecdotal. Elisa Bassignana, Amanda Cercas Curry, and Dirk Hovy's ACL 2025 paper, The AI Gap—which won the conference's Best Social Impact Paper award—surveyed 1,000 individuals and analyzed 6,482 real LLM prompts annotated with sociodemographics. Higher-SES users wrote shorter, more abstract, more concise prompts. Lower-SES users wrote longer, more concrete prompts that anthropomorphized the model—"hello" and "thank you." Mean prompt length: 27 words for low-SES users, 18.4 for upper-class. The authors echo Basil Bernstein's 1960s sociolinguistics on class-based language differences: the high-SES user is deploying inherited cultural capital—abstract reasoning, concise institutional address—to talk to the machine. The machine, trained on the high-SES corpus of the open internet, talks back better.
A separate Cornell-CMU collaboration by Yu, Zhao, Alvero, and Kizilcec analyzed roughly 1.1 million writing submissions from a public minority-serving institution and found that LLMs raised writing quality across the board—but the gains were "more concentrated among students with higher socioeconomic status." AI is not the great equalizer of admissions essays. It is the great accelerator of preexisting inequalities in cultural capital, prompt engineering, and adult mediation.
The infrastructure underneath the gap is similarly stratified. Pew Research's December 2025 survey found 62 percent of teens in $75,000-plus households use ChatGPT; only 52 percent of teens in lower-income households do. 22 percent of households earning under $25,000 rely on cell-only internet, versus 8 percent of households earning over $250,000. Iterative cut-paste-revise prompt engineering on a phone is brutal. ChatGPT Plus is $20 a month, ChatGPT Pro is $200, Claude Max is $100—several hundred dollars a year a working-class family will not spend on a chatbot subscription. The free tier of ChatGPT in 2024–25 frequently silently downgraded to GPT-4o-mini after message caps—exactly the truncated, generic prose that Bassignana's "concrete, anthropomorphic" prompts already produce. Lee herself put it directly to Inside Higher Ed: "High-income students have a lot of different resources; they have counselors, they have teachers, they have more support on top of ChatGPT… [low-income students] might only be able to use the free tier instead of the $200-per-month [version of] Claude, and the quality of the outcome of what free-tier ChatGPT gives us is really poor."
VII. The financial logic of admitting the really rich
None of this works without the deeper question: why would universities—especially universities that loudly proclaim need-blind admissions and equity values—design and tolerate a system that consistently produces these outcomes? The answer is the part the admissions deans never say out loud: tuition revenue and connections to wealthy donors.
Stephen Burd's Undermining Pell series at New America has been documenting the answer for over a decade. At 89 percent of the 479 private nonprofit colleges Burd examined, students from families earning under $30,000 a year faced average net prices over $10,000—over half of family income. At 60 percent, net price exceeded $15,000. Burd's 2020 Crisis Point report found public four-year institutions spent at least $32 billion on non-need-based aid between 2001 and 2017, with the University of Alabama leading at $136 million annually (rising to $185 million by 2023). A 2026 Burd update identified 23 selective private universities and 18 public flagships that spent $2.4 billion in a single year (2023) on non-needy students. Pepperdine charged the lowest-income families about $36,000 a year; Quinnipiac $31,000; Fordham $31,000.
This is enrollment management—the algorithmic discipline of squeezing the maximum tuition revenue from each admitted class. The dominant firms—EAB (which absorbed Royall & Co.), Ruffalo Noel Levitz, Maguire Associates, Othot/Liaison, Encoura—sell predictive tools that direct institutional aid not to the neediest students but to the wealthier students whose enrollment can be tipped with the smallest discount. RNL's Class Optimizer and Yield Campaign products are sold openly. EAB's Nathan Mueller, quoted in NYT Magazine: "The concept is to award financial aid in a way that results in the maximum total amount of net tuition revenue for the institution." Burd in The Chronicle (June 2025): "Congress has never focused on EAB or Noel Levitz or any of these companies. There's a question as to whether financial-aid leveraging itself should be prohibited." Robert J. Massa, retired Dickinson VP for enrollment, was candid about what "merit aid" actually means: scholarships are "awarded because the institution needs to leverage that money in order to maximize their chance of enrolling that student"—not as a reward for prior achievement.
NACUBO's 2024 study put the average tuition discount rate at private nonprofits at 56.3 percent for first-time, full-time undergraduates—an all-time high. The high-tuition/high-discount model that Cornell economist Ronald Ehrenberg documented in Tuition Rising (2000) has metastasized. Sticker price funds amenities, rankings climbs, and the bidding war for desirable students. The desirable students are by and large the ones whose enrollment requires only modest discounting—i.e., the wealthy.
The Henry v. Brown private antitrust class action, filed in 2022 against 17 universities including Yale, Penn, Brown, Columbia, Duke, MIT, Northwestern, Notre Dame, Caltech, and Chicago, revealed in discovery what the schools' need-blind disclaimers had hidden for decades: development-office input compromised the supposedly need-blind admissions firewall. Yale settled for $18.5 million. Brown $19.5 million. Emory $18.5 million. Columbia, Duke, Vanderbilt—all settled. The lawsuits did not produce structural reform. The settlements were a cost of doing business.
In this financial machine, what does an LLM-using lower-SES applicant look like? Like a low-yield prospect, especially when elite schools feel confident they have already checked that box with their QuestBridge applicants. (Ever wonder why the most elite schools somehow admit virtually the same number of QuestBridge applicants while claiming to do an individual holistic review?) A typical lower-SES applicant looks like a student whose admission would require a large discount, whose retention is statistically less certain, whose post-college donations will be smaller, and whose essay—for the reasons Lee et al. documented—gives the admissions office a defensible reason to reject. The institutional preference for wealth, formalized in legacy and athletic and donor preferences, doesn't cause the LLM penalty in any clean mechanical sense. It conditions the entire reading environment. Of course readers find the wealthy student's polished essay convincing; of course they find the poor kid's polished essay suspicious. The institution's revenue model and the readers' priors are pointing the same direction.
VIII.Verdict: an old machine running a new program
Return to the original question: is the LLM penalty for lower-SES students best understood as (a) a new manifestation of existing class bias, (b) a direct result of detection-tool bias, (c) a symptom of admissions offices' deeper preferences for wealth and power, or (d) some combination?
The evidence supports a layered "all of the above"—but with strong weight on (c).
Detection bias is real and quantified. The Liang et al. 61 percent false-positive rate on TOEFL essays, OpenAI's 9 percent native false-positive rate, Turnitin's chief product officer admitting the model "learns that more complex writing is more likely to be human"—these are not contested facts. Where commercial detectors are being deployed (and they are being deployed widely, sometimes via Slate's embedded AI, sometimes via Pangram, sometimes via institutional builds like UNC and Virginia Tech), the lower-SES student walks into a structurally rigged perplexity test.
But human readers do most of the work. Lee et al.'s mediation finding—only 7.1 percent of the differential explained by observable stylometry—is the single most important data point in their paper. The penalty is not in the prose. Kadoma, Metaxa, and Naaman's CHI 2025 experiments establish that suspicion alone, separate from any actual AI use, degrades evaluations. Bastedo's experimental work establishes that absent contextual scaffolding only 29 percent of admissions readers default to "whole context" review—the rest fall back on heuristics, including stereotypes about whose voice should sound which way. Huang's authenticity paradox names the trap: lower-SES students must perform identity legibly, but their legible performances will be coded as inauthentic if too polished. Alvero's 2024 finding that AI-generated prose mimics the high-SES register completes the circle: when poor kids produce that register, by AI or otherwise, readers have a ready-made reason to demote them.
And the institution's deeper preferences shape every layer of this. Karabel's history makes clear that "holistic" admissions was always discretionary cover for institutional sorting. Arcidiacono's 33.6 percent legacy admit rate, 86 percent athlete admit rate, 42.7 percent Dean's Interest List admit rate, and the roughly 30 percent of admits accounted for by ALDC categories establish that the institution is already functioning as a wealth-preserving filter before any LLM enters the room. Chetty/Friedman/Deming's top-1 percent 2.2x advantage establishes the same pattern across Ivy-Plus. Stephen Burd's $2.4 billion-a-year merit-aid leveraging documents the financial logic that makes admitting the wealthy preferable. Daniel Golden's Kushner $2.5 million, Bass $25 million, the Frist Campus Center—these are the named cases. The unnamed cases are the iceberg.
The detection tools, where used, magnify the bias. The reader judgments do most of the punishing. The institutional self-interest is what makes the system durable.
Wealthy applicants get the technology routed through $30,000 consultants, $200/month chatbot subscriptions, prompt-engineering tutors, and humanizer apps; their AI-assisted essays match the rest of their elite-prep file and pass through readers as ordinary polish. Lower-SES applicants get the technology in raw form, route their working-class voice through it, and produce prose that diverges from the rest of their application file in ways readers—primed by similarity bias, the authenticity paradox, and a century of institutional muscle memory about who "belongs"—will read as suspect.
A genuinely meritocratic admissions office would be alarmed by the Lee et al. findings and would change its essay-evaluation rubric, audit its readers for similarity bias, refuse to deploy detection tools that fail Liang's test, and weight contextual factors heavily for lower-SES applicants. A few schools have done versions of this—Duke under Christoph Guttentag stopped assigning numerical ratings to essays in 2024; Georgia Tech's Rick Clark has publicly told his readers to stop worrying about AI detection and focus on specificity and voice. These are exceptions. The rule, established over a century and confirmed by every quantitative data dump from SFFA to Chetty, is that selective American admissions exists to reproduce the social position of the institutions and their alumni base. It always has. The chatbot is just the latest test of who passes.
The Lee et al. paper notes carefully, in its limitations section, that the case institution is unnamed and the mechanisms are not causally identified. Both caveats are fair. But the larger question the study raises is not really empirical; it is institutional. Which version of the admissions office do you believe:
- The one in the press release, that values authentic voice and supports first-generation students?
- Or the one in the Z-list memos, the Dean's Interest List spreadsheet, the EAB yield models, the Henry v. Brown discovery, and the 1925 letter to A. Lawrence Lowell about the "Hebrewization" of Harvard?
Lee et al. simply added one more data point to the case file. The case is old.